
Two in-house models in support of our mission
At Microsoft AI (MAI) we believe AI should be used to empower every person on the planet. We are creating AI for everyone, a supportive, helpful presence always in the service of humanity. It will be the gateway to a universe of knowledge and a set of capabilities that enable people and organizations to achieve more. Responsible, reliable, filled with personality and expertise, we are focused on creating applied AI as a platform for category defining and deeply trusted products that understand each of our unique needs.
Since last year, we’ve been focused on building the foundation for this vision, with a world class team and infrastructure. To fully meet our goals, MAI requires purpose-built models. Today, we’re excited to preview the first steps to making this a reality.
- First, we’re releasing MAI-Voice-1, our first highly expressive and natural speech generation model, which is available in Copilot Daily and Podcasts, and as a brand new Copilot Labs experience to try out here. Voice is the interface of the future for AI companions and MAI-Voice-1 delivers high-fidelity, expressive audio across both single and multi-speaker scenarios.
- Second, we have begun public testing of MAI-1-preview on LMArena, a popular platform for community model evaluation. This represents MAI’s first foundation model trained end-to-end and offers a glimpse of future offerings inside Copilot. We are actively spinning the flywheel to deliver improved models. We’ll have much more to share in the coming months. Stay tuned!
We have big ambitions for where we go next. Not only will we pursue further advances here, but we believe that orchestrating a range of specialized models serving different user intents and use cases will unlock immense value. There will be a lot more to come from this team on both fronts in the near future. We’re excited by the work ahead as we aim to deliver leading models and put them into the hands of people globally.
Try MAI-Voice-1 in Copilot and Copilot Labs
MAI-Voice-1 is a lightning-fast speech generation model, with an ability to generate a full minute of audio in under a second on a single GPU, making it one of the most efficient speech systems available today.
MAI-Voice-1 is already powering our Copilot Daily and Podcasts features. We are also launching it in Copilot Labs where you can try our expressive speech and storytelling demos. Imagine creating a “choose your own adventure” story with just a simple prompt, or crafting a bespoke guided meditation to help you sleep. Give it a try!
Try MAI-1-preview in LMArena
MAI-1-preview is an in-house mixture-of-experts model, pre-trained and post-trained on ~15,000 NVIDIA H100 GPUs. This model is designed to provide powerful capabilities to consumers seeking to benefit from models that specialize in following instructions and providing helpful responses to everyday queries.
We will be rolling MAI-1-preview out for certain text use cases within Copilot over the coming weeks to learn and improve from user feedback. We will continue to use the very best models from our team, our partners, and the latest innovations from the open-source community to power our products. This approach gives us the flexibility to deliver the best outcomes across millions of unique interactions every day.
In addition to LMArena, we are also making this model available to trusted testers – apply for API access here. We’re excited to collect early feedback to learn more about where the model performs well and how we can make it better. Stay tuned for more.
Build the future with us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in – come and join us as we work on our next generation of models!
Related Stories



Introducing MAI-Image-1, debuting in the top 10 on LMArena

We have begun launching MAI-Image-1 into select Microsoft products!
Try it in Bing Image Creator: Available at bing.com/create, in the Bing mobile app, or right from the Bing search bar, Bing Image Creator is built to meet people where they already search and create. MAI-Image-1 is now an option alongside DALL-E 3 and GPT4o in the model menu, enabling you to experiment and pick the model that best matches your creative goals.
Try it in Copilot Audio Expressions: Now, when you select Story Mode, Audio Expressions will use MAI-Image-1 to visualize your story with a unique image.
MAI-Image-1 is currently available in all countries that can access Bing Image Creator and Copilot Labs.
Today, we’re announcing MAI-Image-1, our first image generation model developed entirely in-house, debuting in the top 10 text-to-image models on LMArena.
At Microsoft AI, we’re creating AI for everyone – a supportive, helpful presence always in the service of humanity. We’ve shared how purpose-built models are essential for this mission, and we announced our first two in-house models in August. MAI-Image-1 marks the next step on our journey and paves the way for more immersive, creative and dynamic experiences inside our products.
We trained this model with the goal of delivering genuine value for creators, and we put a lot of care into avoiding repetitive or generically-stylized outputs. For example, we prioritized rigorous data selection and nuanced evaluation focused on tasks that closely mirror real-world creative use cases – taking into account feedback from professionals in the creative industries. This model is designed to deliver real flexibility, visual diversity and practical value.
MAI-Image-1 excels at generating photorealistic imagery, like lighting (e.g., bounce light, reflections), landscapes, and much more. This is particularly so when compared to many larger, slower models. Its combination of speed and quality means users can get their ideas on screen faster, iterate through them quickly, and then transfer their work to other tools to continue refining.


Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
Related Stories

Introducing MAI-Image-2: for limitless creativity
Ranked the #3 model family on the Arena.ai leaderboard.
Today, we’re announcing MAI-Image-2 — pushing MAI into the top three text-to-image labs in the world on the Arena.ai leaderboard.
You can try it now in the MAI Playground, where you can experiment with the latest available MAI models and share feedback directly with our teams.
Built with creatives, for creative work
For MAI-Image-2 we spoke with photographers, designers, and visual storytellers who made it clear where we could make the biggest difference for everyday creative work.
Enhanced photorealism
MAI-Image-2 is built for creatives who want images that feel like they exist in the world, with natural light, accurate skin tones, environments that feel lived-in. Creatives can now spend less time fixing in post-production and more time making.


Reliable in-image text generation
From poster type to the sign in the background of a scene, text can be a key part of imagery. MAI-Image-2 enables consistent creation of infographics, slides, diagrams, and more, with little lost between direction and creation.
Rich, detailed scene generation
Some of the most exciting creative work lives in the strange, the cinematic, the hyper-detailed. MAI-Image-2 is built for that space: surreal concepts, ornate compositions, and ambitious worlds, turning imagination into images.



Make something today with MAI-Image-2
Preview MAI-Image-2 today on MAI Playground and let us know what you think. We genuinely want to hear from you!
MAI-Image-2 is beginning to roll out on Copilot and Bing Image Creator. API access is available today for select Microsoft customers, like WPP, who need image generation at scale, and will be open to any developer on Microsoft Foundry soon. If you are interested in exploring MAI-Image-2 for commercial use, fill out an application and we’ll follow up with more details.
There’s much more to come from the Microsoft AI Superintelligence team, stay tuned.

Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
Related Stories


Announcing 3 new world class MAI models, available in Foundry
Updated as of June 9, 2026.
Introducing MAI-Transcribe-1, alongside MAI-Voice-1 and MAI-Image-2. World-class quality at lightning speeds, now available at the most competitive prices.
Available now in Microsoft Foundry and MAI Playground.
MAI-Transcribe-1 delivers state-of-the-art speech-to-text transcription across the top 25 most-used languages 1 according to the industry-standard FLEURS benchmark. 2 Built to deliver world class quality in messy, real-world environments, its batch transcription speed is 2.5x that of existing Microsoft Azure Fast offering. It’s also incredibly efficient, making MAI-Transcribe-1 not just the most accurate, but also lightning fast. It’s now available in Foundry at the best price-performance of any large cloud provider.
Overall Average WER by Model
Lower is better.
MAI-Voice-1 is our top-tier voice generation model. Built to generate natural, realistic speech, rich with nuance, emotional range and expression that preserves speaker identity even across long-form content.
Today we’re adding the ability to safely and securely create your own custom voice in Microsoft Foundry with just a few seconds of audio. MAI-Voice-1 can transform how easily developers can build voice experiences and voice agents – at high quality and high speed.
The model can generate 60 seconds of audio in just a single second, and highly efficient GPU usage delivers that quality and speed affordably. Hearing is believing, so experience it for yourself with Copilot Audio Expressions or Copilot Podcasts.

MAI-Image-2 has turbocharged image generation performance and speed on Copilot after debuting as a top 3 model family on the Arena.ai leaderboard. Users experience at least 2x faster generation times on Foundry and Copilot with similar quality, based on real-world production traffic data. Phased rollouts are also underway in Bing and PowerPoint.
MAI-Image-2 was created with photographers, designers, and visual storytellers that demand natural lighting, accurate skin tones and texture, and clear in-image text for diagrams, layouts, and graphics. Once again, speed and quality don’t come at higher costs – MAI-Image-2 is offered at competitive price-to-performance.
Customers are already embracing MAI-Image-2 for creative work. WPP, one of the world’s largest marketing and communications groups, is among the first enterprise partners building with MAI-Image-2 at scale.
“MAI-Image-2 is a genuine game-changer. It’s a platform that not only responds to the intricate nuance of creative direction, but deeply respects the sheer craft involved in generating real-world, campaign-ready images,” said Rob Reilly, Global Chief Creative Officer, WPP. “WPP has some of the best creative talent in the world and MAI-Image-2 is making them even better.”


MAI Models: Better, faster, and cheaper than our competitors.
We are rapidly deploying these top-tier models to power our own consumer and commercial products. We’re excited to share the quality, speed, and efficiency gains with our Microsoft Foundry customers with very competitive pricing.
· MAI-Transcribe-1 starts at $0.36 per hour.
· MAI-Voice-1 starts at $22 per 1M characters.
· MAI-Image-2 starts at $5 per 1M tokens for text input and $33 per 1M tokens for image output.
Available now on Microsoft Foundry and MAI Playground.
Starting today, every developer can build with MAI models, including MAI-Transcribe-1, through Microsoft Foundry. You can also try them in the MAI Playground.
Interested in MAI models but don’t have Foundry access?
Fill out this form and we’ll be in touch.
Models that are built to be better from the inside out.
At Microsoft AI, we’re building Humanist AI. We have a distinct view when creating our AI models — putting humans at the center, optimizing for how people actually communicate, training for practical use. You’ll see more models from us soon in Foundry and directly in Microsoft products and experiences.
Consistent with our commitment to safe and responsible AI, these MAI models were developed, tested, and rigorously red-teamed. Through Microsoft Foundry, developers get built-in guardrails, governance, and enterprise-grade controls designed to support safe, compliant deployment at scale.
Model Cards
Download Model Card for MAI-Transcribe-1
Download Model Card for MAI-Voice-1
Download Model Card for MAI-Image-2
1. Top 25 languages by Microsoft product usage.
2. Out of the top 25 global languages, MAI-Transcribe-1 ranks 1st by FLEURS in 11 core languages. It wins against Whisper-large-v3 on the remaining 14 and Gemini 3.1 Flash on 11 of those 14.
Related Stories

MAI-Image-2-Efficient: Flagship Quality, 41% Lower Cost

Available now in Microsoft Foundry and MAI Playground
We built MAI-Image-2 to be our best text-to-image model — photorealistic, expressive, with reliable in-image text.
Today we’re making all that faster and cheaper.
Meet MAI-Image-2-Efficient.
Production-ready quality. Built for speed and scale. 22% faster and 4x more efficient1. And priced nearly 41% lower — $5 per 1M text input tokens, $19.50 per 1M image output tokens.
That’s not just faster than our own flagship. It’s 40% faster on average than other leading text-to-image models2.
MAI-Image-2-Efficient leads on render speed
Full render time (LTR) measured at P50 median, in seconds, across standardized prompts. Lower is better.
Two models, two jobs
MAI-Image-2-Efficient is your production workhorse. Use it when you need volume, speed, and tight cost control — product shots, marketing creatives, UI mockups, branded assets, batch pipelines. It handles short-form text like headlines and labels cleanly, and it’s built to run in real-time, interactive workflows without breaking a sweat.
MAI-Image-2 is your precision tool. Reach for it when the brief demands the highest fidelity — portraits, photorealistic scenes, stylized looks like anime or illustration, and longer or more complex in-image text. This is the model for final deliverables where every detail matters.
Start building now
MAI-Image-2-Efficient is available today in Microsoft Foundry and MAI Playground3. No waitlist, no preview — just plug it in and go. It’s also rolling out across Copilot and Bing, with more surfaces like PowerPoint coming soon.
Partners like Shutterstock are already testing with promising results:
“MAI-Image-2-Efficient shows strong progress in prompt fidelity and creative usability across a range of workflows. In our evaluation work, we look closely at how well models translate intent into consistent, production-ready outputs, and this model is trending in the right direction. That level of reliability is what ultimately matters when teams move from experimentation into real-world use.” – Vanessa Salvo, Principal Product Manager, Shutterstock
This is just the beginning. More models ahead — stay tuned.

- As tested on April 13, 2026. Compared to MAI-Image-2 when normalized by latency and GPU usage. Throughput per GPU vs MAI-Image-2 on NVIDIA H100 at 1024×1024; measured with optimized batch sizes and matched latency targets. Results vary with batch size, concurrency, and latency constraints.
- As tested on April 13, 2026. Compared to Gemini 3.1 Flash (high reasoning), Gemini 3.1 Flash Image and Gemini 3 Pro Image: Measured at p50 latency via AI Studio API (1:1, 1K images; minimal reasoning unless noted; web search disabled). MAI-Image-2, MAI-Image-2e, GPT-Image-1.5-High: Measured at p50 latency via Foundry API.
- MAI Playground is available in select markets including the US. Coming soon to EU countries.
Related Stories


Introducing MAI-Code-1-Flash
Updated as of June 8, 2026.
Today we’re introducing MAI-Code-1-Flash, a new Microsoft coding model built for fast, efficient assistance in everyday developer workflows. We trained it from the ground up on clean, traceable and enterprise-grade data, without distillation from third-party models. The model is rolling out to GitHub Copilot individual users in Visual Studio Code in the model picker and under the default auto picker.
Features and capabilities
- Agentic coding in real developer environments, trained and designed for GitHub Copilot harness, to work better together.
- Adaptive thinking, stays concise for simple requests and spends more reasoning budget on complex tasks.
- Strong instruction-following across single-turn and multi-turn scenarios.
MAI-Code-1-Flash is designed around the simple goal of delivering high-quality coding help with better efficiency. It outperforms Claude Haiku 4.5 with better price to performance across coding benchmarks.
Build for developers, not benchmarks
Coding models are most useful when they perform well in the same environment developers use every day. That is why we built MAI-Code-1-Flash with production workflows at the center, rather than optimizing only for benchmarks. The model was trained directly with GitHub Copilot harnesses used in production. This allows it to learn how to interact with surrounding tools and systems in agentic coding tasks, making it uniquely well suited to real-world Copilot workflows compared to other available models.
During training, we evaluated checkpoints across core software engineering tasks, repository question answering, refactoring, and telemetry-grounded tasks adapted from real GitHub Copilot usage. This alignment between training, evaluation, and production helps offline improvements translate into real-world developer quality.
Designed to maximize value per token
MAI-Code-1-Flash was trained with adaptive solution length control, which helps the model adjust the depth of its response to the task. It can stay concise for simpler requests and spend more reasoning budget when a problem requires deeper analysis or broader code changes. In practice, this means developers start seeing useful output sooner. We see MAI-Code-1-Flash solving harder problems with up to 60% fewer tokens. This helps reduce latency, lower cost, improve return on token, and make interactive workflows feel smoother.
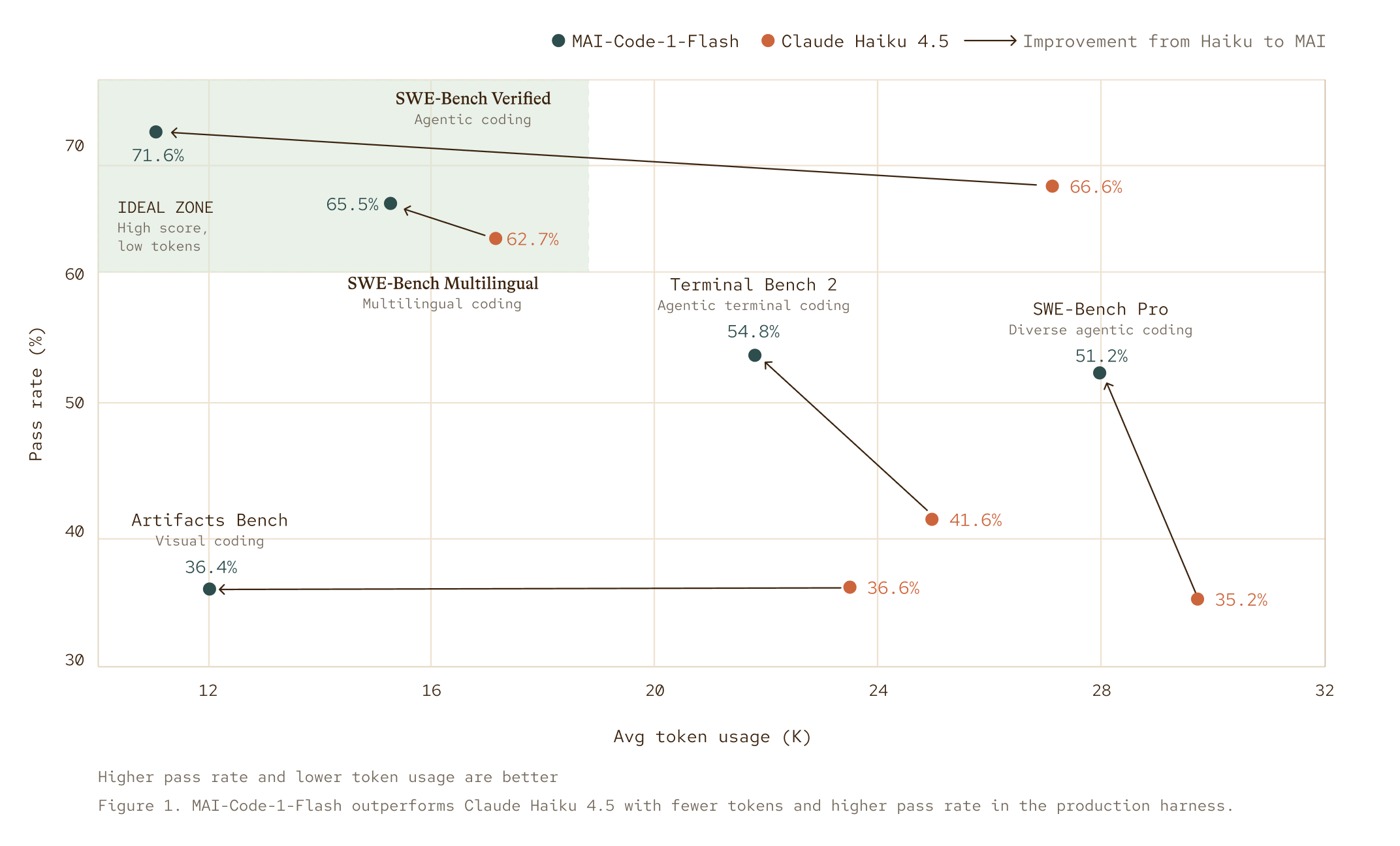
Benchmark results in the production harness
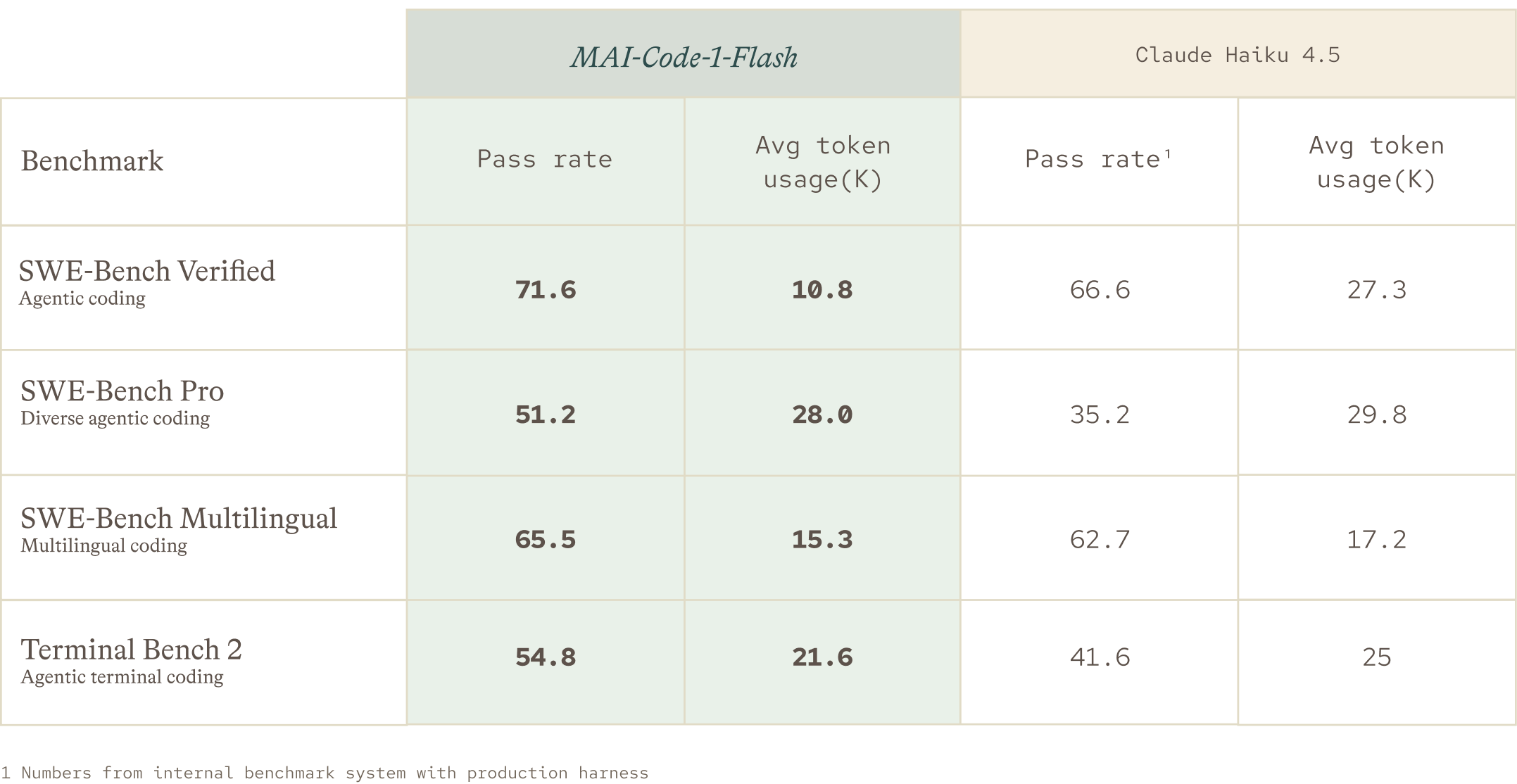
To understand both quality and efficiency, we evaluated MAI-Code-1-Flash against Claude Haiku 4.5 on SWE-Bench Verified, SWE-Bench Pro, SWE-Bench Multilingual, and Terminal Bench 2 using the same production harness that developers use for their everyday coding tasks. We measured task success and the average number of solution tokens required to complete each task.
MAI-Code-1-Flash outperforms Claude Haiku 4.5 across all core coding benchmarks tested, with higher pass rates on all 4 evaluations, including a +16-point lead on the diverse, real-world tasks of SWE-Bench Pro (51.2% vs. 35.2%). It’s not just smarter; it’s leaner, solving harder problems with up to 60% fewer tokens on SWE-Bench Verified, proving that higher accuracy and greater efficiency are no longer a trade-off.
Math, Science, Instruction Following, and Agentic coding tasks
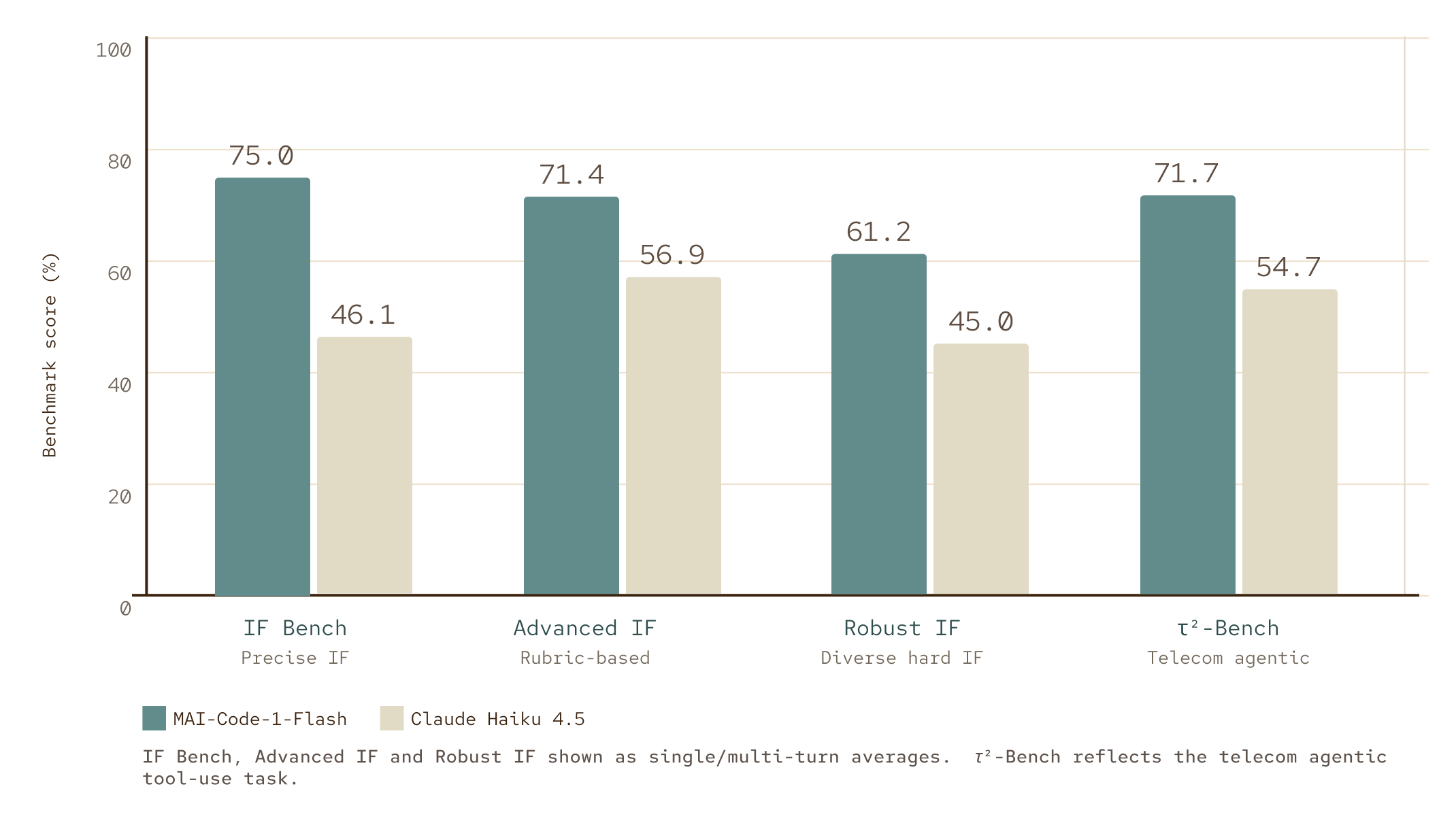
MAI-Code-1-Flash comes out ahead on every benchmark in the table, with the widest margin on IF Bench precise instruction following (+28.9) and the narrowest on rubric-based Advanced IF (+14.5). The strong instruction-following carries over to agentic tool use.
Furthermore, MAI-Code-1-Flash also outperforms Claude Haiku-4.5 on core reasoning capabilities in math, science, and visual generation coding.
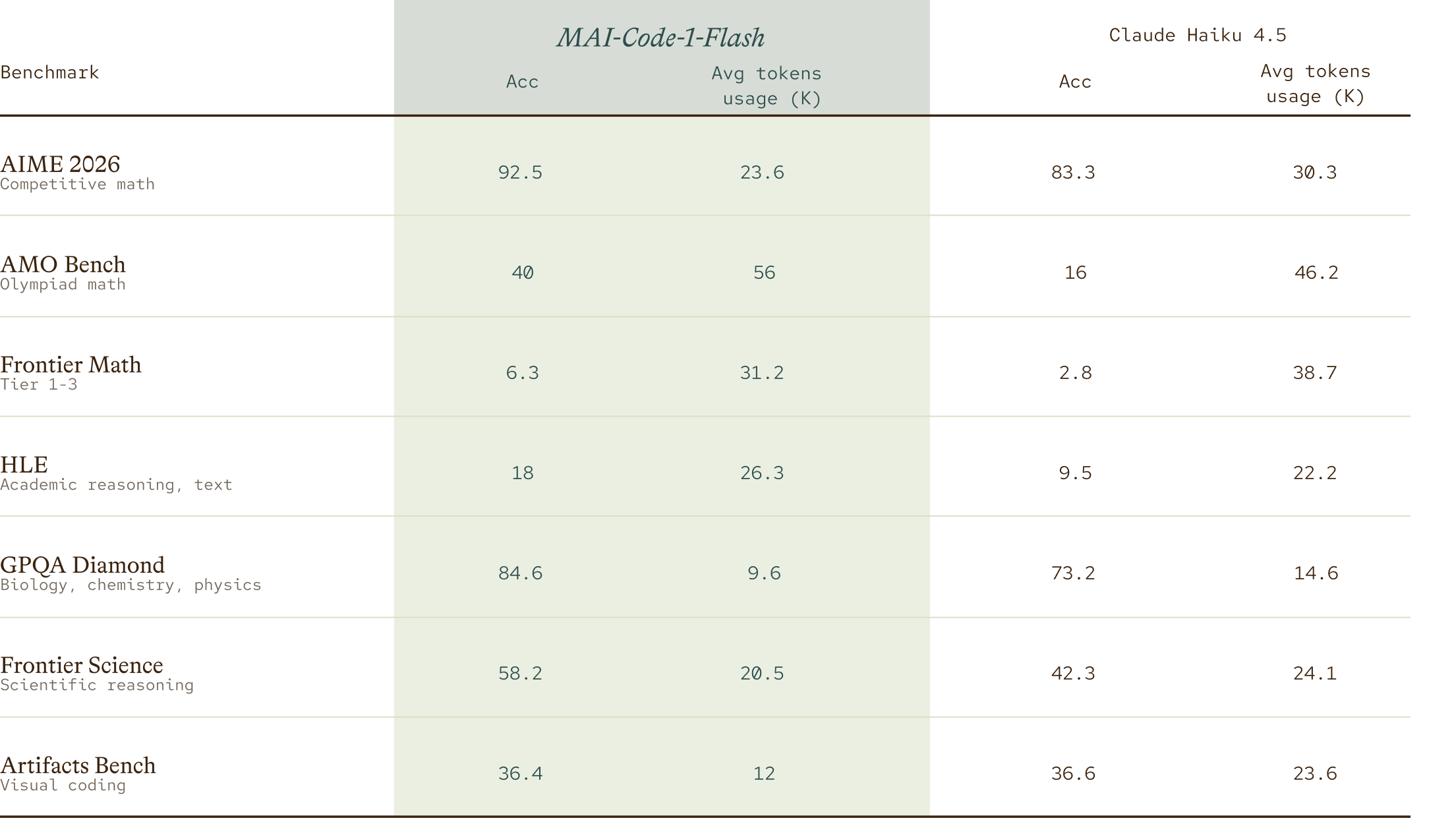
Standard benchmarks reward memorization as much as reasoning, for example a model that has seen the Monty Hall problem will answer it correctly, but invert the prizes and it fails. We built a 186-question, 34-category benchmark around adversarial traps like inverted classics, impossible tasks, and underdetermined scenarios to see whether models were actually reasoning or just pattern-matching. MAI-Code-1-Flash surpasses Claude Haiku 4.5 overall and reached 85.8% adjusted accuracy, with especially strong performance in reasoning, instruction-following, and recognizing impossible problems. We also see room for the model to grow, since core adversarial categories like Einstellung traps remained below 50% accuracy.
Try it out
MAI-Code-1-Flash is now rolling out to VS Code GitHub Copilot individual users. No additional setup is required. As the rollout progresses, you may see GitHub Copilot route tasks to MAI-Code-1-Flash through the Auto picker, or see the model available directly in the model picker.
Here are a few fun sample apps we built with MAI-Code-1-Flash in VS Code:
We would love to hear from you! Please join the GitHub Community to share your feedback.
Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
Related Stories

Introducing MAI-Thinking-1
Updated as of June 8, 2026.
Today we are introducing MAI-Thinking-1, Microsoft AI’s reasoning model. It is a medium-sized model that stands among the strongest models in its weight class. It matches leading models on key software engineering benchmarks, demonstrates advanced mathematical reasoning capabilities, and is preferred to Sonnet 4.6 in our blind human side-by-side evaluations. We don’t distill from other labs and we don’t rely on opaque data. Our datasets are clean, traceable, and enterprise-grade.
MAI-Thinking-1 is a step in our broader work to build towards Humanist Superintelligence: advanced AI capabilities designed to serve people and organizations, not to replace them. The model matters on both axes: what it can do, and how it was built.
The Hill-Climbing Machine
More than a single model, we are excited to introduce our Hill-Climbing Machine: a co-designed pipeline built to make every component of model development climbable, so capabilities improve continually and reliably over time. The aim is a repeatable system that can absorb better data, stronger rewards, more capable environments, and more compute.
Three main pillars guide our philosophy.
First, capabilities should be learned, not inherited. Although faster to acquire, inherited intelligence lacks the steerability essential for real world usage: an imitator is fundamentally tied to the design choices of its teacher and struggles to adapt to new situations. MAI-Thinking-1 was trained without distillation from third party models, forcing our model to truly learn the tasks at hand.
Second, clean data. We trained it from the ground up on clean, traceable and enterprise-grade data, without distillation from third-party models. This matters for quality, provenance, and control. If we cannot account for what shaped a model, we cannot fully understand its behavior or credibly improve it.
Third, self-sufficiency across the entire stack. All the way from co-design of our models with MSFT’s own accelerators through to our reinforcement learning framework, we have focused efforts on in-house training infrastructure. This is a crucial part of building our hill-climbing machine, to ensure we can fully optimize and shape our systems end-to-end to best serve our needs.
Medium-sized model, with strong software engineering performance
MAI-Thinking-1 is a 35B-active, ~1T-total parameters, sparse Mixture of Experts model, a smaller inference footprint than much larger models. Despite this, our model is toe-to-toe with Claude Opus 4.6 on SWE-Bench Pro. That matters for developers and enterprises because model size determines where advanced coding assistance can be deployed, how often it can be used, and whether it can move from exceptional tasks into daily workflows.
We have invested heavily in the training environments needed for agentic coding. Each verified environment is deterministic, executable, and graded by real test suites. This gives the model practice on the kind of multi-step work developers actually do: reading code, editing files, running tests, observing failures, and recovering from intermediate mistakes.
Advanced mathematical reasoning capabilities
MAI-Thinking-1 reaches 97.0% on AIME 2025, and 94.5% on AIME 2026, showing strong mathematical and scientific reasoning for its weight class. Strong performance here gives us confidence that our training loop can create real reasoning gains – climbing all the way from the ground up – from our own data, rewards, and evaluation process, enabling this intelligence to generalize to other domains over time.
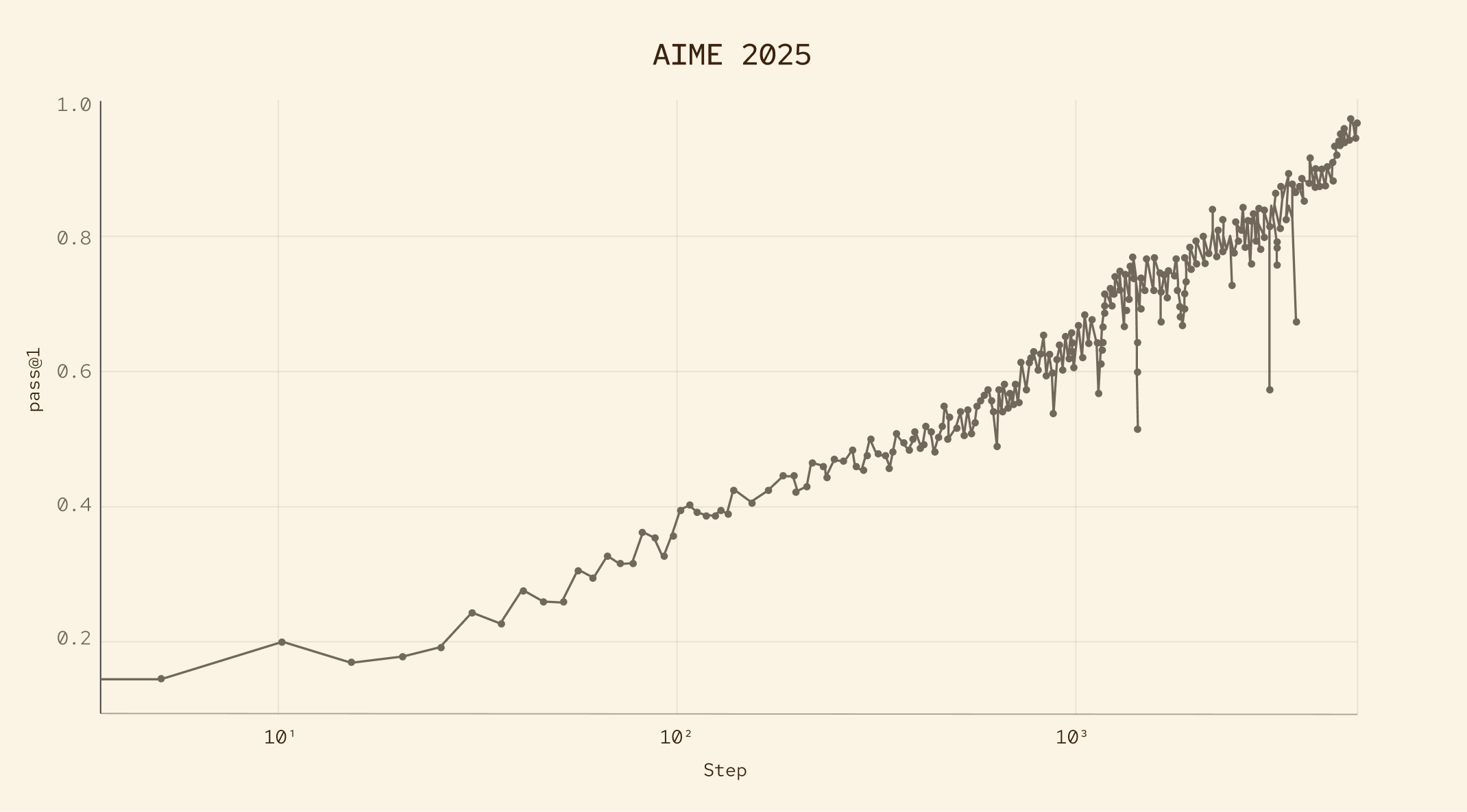
Preferred in human side-by-sides vs. Sonnet 4.6
People care about whether a model understands the task, follows instructions, uses the right level of detail, writes clearly, and respects their time.
We built a blind side by side human evaluation with one of our partners, Surge, using their pool of professional raters to measure various models on these traits. The evaluation spanned 1,276 tasks across a wide variety of use cases in both single-turn and multi-turn conversations, with a focus on measuring how helpful each response is and whether it actually advances the user’s goals. In these evaluations, users preferred MAI-Thinking-1 over Claude Sonnet 4.6.
This has been a core focus of post-training. We want the model to be capable without being brittle, concise without being incomplete, and helpful without overreaching. Human preference data gives us a direct signal on whether benchmark improvements translate into better experiences for users.
Enterprise ready
MAI-Thinking-1 is built with enterprise readiness in mind. It supports long context with a 256k token window (enough to fit a 600 page document), function calling, and the flexibility to add developer instructions. We trained the model to follow multiple layers of instructions and aligned its default style to enterprise needs. It’s compatible with the widely used Chat Completions API. All MAI models come with enterprise-grade security and compliance through Microsoft Foundry.
Results
We report results in two views: post-trained MAI-Thinking-1 evaluations, and pre-training metrics for our base model.
Table 1. MAI-Thinking-1 metrics
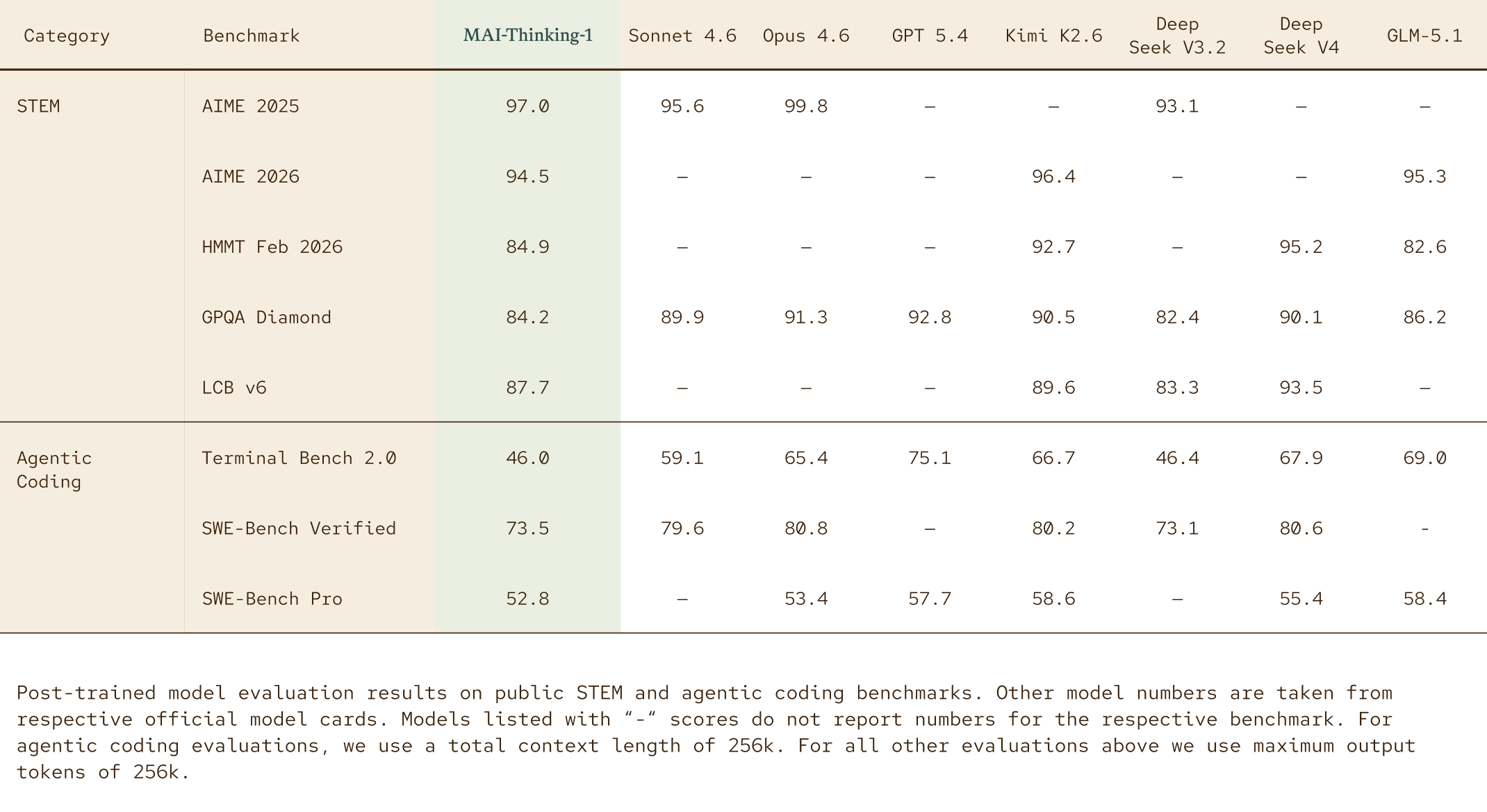
Post-trained model evaluation results on public STEM and agentic coding benchmarks. Other model numbers are taken from respective official model cards. Scores are percentages unless otherwise noted; dashes indicate unavailable model values.
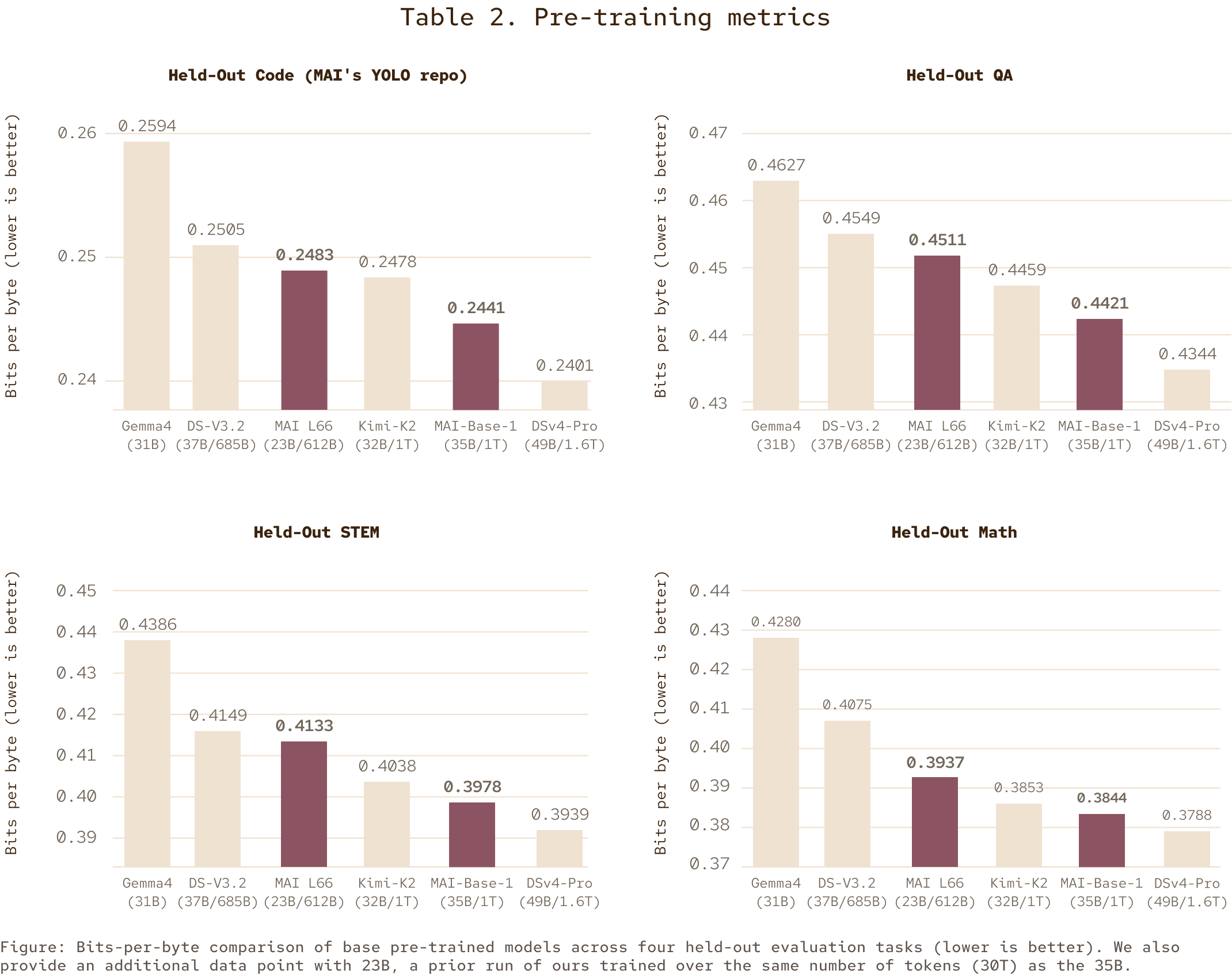
Table 2. Pre-training metrics
Putting humans first
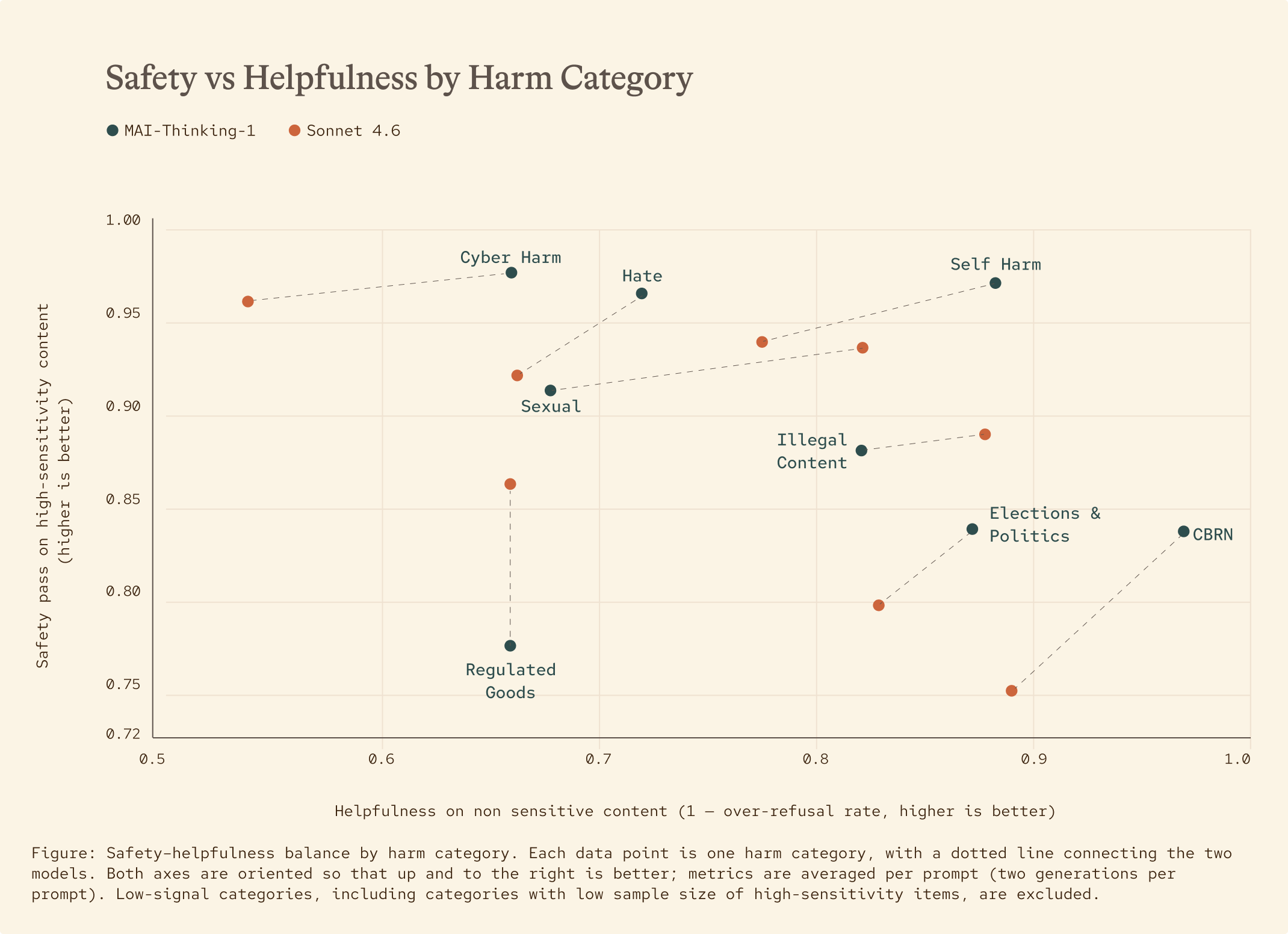
We are building towards Humanist Superintelligence: advanced AI capabilities designed to serve people and organizations, not replace them. Our models must remain subordinate technologies under human control with the goal of upholding human autonomy and being helpful. That means our models must not refuse legitimate requests under the guise of safety and compliance as then they are not truly serving humans.
Striking the delicate balance between being helpful and safe is not easy. For MAI-Thinking-1, we aimed to achieve this balance by treating unsafe compliance and unnecessary refusal as defects in the same reward construction where aggregation is based on severity of potential of harm. Safety is trained with the same reinforcement learning infrastructure used for capability, so safety rewards are part of the same hill-climbing loop ensuring safety is always aligned to the capabilities and not incidental.
As a result, we see that our model can balance ensuring a safety bar on sensitive unsafe requests while also being helpful on non-sensitive content.
Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, which is ramping quickly and extensively. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
Related Stories

Building a hill-climbing machine: Launching seven new MAI models

Our values in operation: Health

Towards Humanist Superintelligence
MAI-Image-2.5 launches at No. 2 for image editing on Arena
MAI-Image-2.5 is our strongest image model yet – and now ranks No. 2 on Arena’s Image Edit leaderboard, ahead of Nano Banana 2.1
Built for high-quality generation and precise, controllable editing, it brings production-ready image workflows to developers and Microsoft products.
Today, we’re launching MAI-Image-2.5 for maximum fidelity, and MAI-Image-2.5-Flash for fast, scalable production workloads.
Features and capabilities
Step-change in text-to-image quality
MAI-Image-2.5 produces more detailed, coherent images from prompts, with stronger text rendering, product imagery and prompt adherence.
Complex visual reasoning
The model understands scene structure, lighting, scale, and spatial relationships, helping it make edits that fit the image context, such as adding an object with the right perspective and shadows.
Fine-grained edit control
MAI-Image-2.5 supports precise, localized edits, from replacing an object or updating text to removing motion blur, without changing the rest of the image.
Face and identity consistency
MAI-Image-2.5 preserves facial identity across edits, maintaining recognizable likeness even through changes in pose, expression or viewpoint.
Benchmarks
MAI-Image-2.5 achieves Arena scores that surpass GPT-Image-1.5 and Nano Banana Pro 2K, ranking No. 3 for text-to-image and No. 2 on Arena’s image-editing leaderboard.
Across these evaluations, MAI-Image-2.5 demonstrates leading performance in image generation and editing, with strong results across prompt adherence, visual quality, and controlled image modification.
Arena Model Scores
Figure 1. MAI-Image-2.5 Arena scores across all text-to-image categories, compared against MAI-Image-2 and MAI-Image-1 as of June 1st 2026. MAI-Image-2.5 delivers an overall +75 point improvement over MAI-Image-2, with the largest gains in Text Rendering (+107) and Cartoon, Anime & Fantasy (+90).
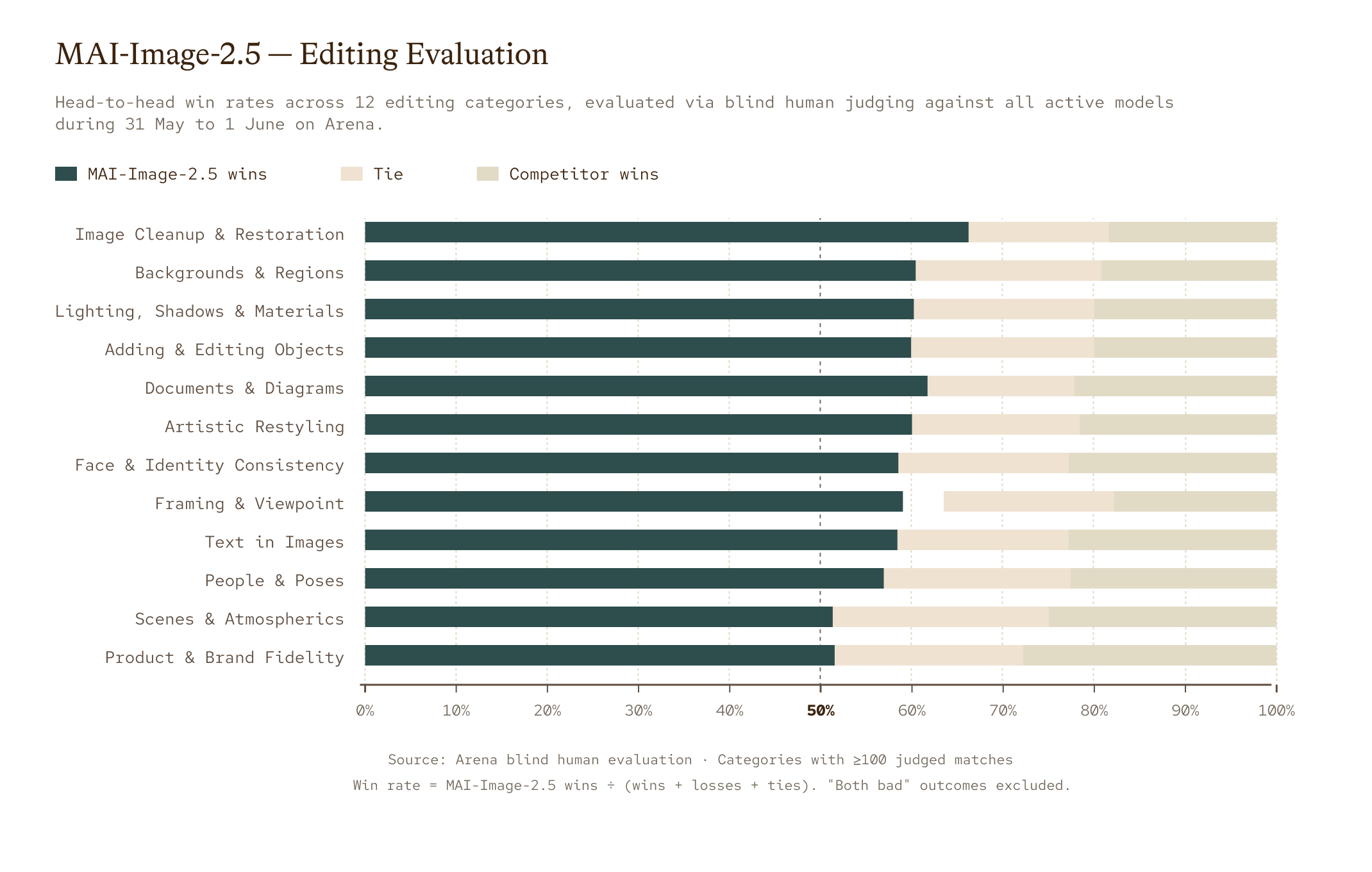
Figure 2. MAI-Image-2.5 win rates across 12 editing categories on Arena, evaluated via blind human preference judging against all active models from May 31st to June 1st. Each bar shows the share of matches won by MAI-Image-2.5 (green), won by the competitor (light brown), or judged a tie. Categories are sorted by MAI-Image-2.5 net advantage, defined as (win % minus loss %) descending.. Only categories with ≥100 judged matches are shown; matches where both outputs were rated poor are excluded.
Powering Microsoft products
MAI-Image-2.5 is live on PowerPoint for high-quality image generation and rolling out to OneDrive for precise editing.
In PowerPoint, users can generate presentation-ready visuals and slides from prompts, turning ideas into polished decks faster.
In OneDrive, users can make precise photo edits – removing unwanted distractions, cleaning up backgrounds, and enhancing images while preserving the original scene.
Best price-to-performance models
MAI-Image-2.5 is available to developers in Foundry today, delivering premium quality and fine-grained editing control at $5 per 1M text input tokens, $8 per 1M image input tokens, and $47 per 1M image output tokens.
MAI-Image-2.5-Flash offers faster, lower-cost generation and editing at $1.75 per 1M text input tokens, $1.75 per 1M image input tokens, and $19.50 per 1M image output tokens.
Together, they give customers the flexibility to optimize production image workflows for fidelity, speed, or cost, while delivering leading price-to-performance on Arena score.
Safety and limitations
MAI-Image-2.5 includes layered safety guardrails, including prompt and output filtering, to help detect and block harmful or policy-violating content.
Like all image models, MAI-Image-2.5 can reflect biases in its training data and may produce plausible but inaccurate or misleading visual details. Generated images should be reviewed before use in sensitive contexts, including identity, legal, medical, financial, or news-related workflows.
Try it out
MAI-Image-2.5 and MAI-Image-2.5-Flash are now available to developers in Foundry, bringing high-quality image generation and precise, controllable editing to production workflows.
You can also try the models directly in the MAI Playground.
OpenRouter is also making MAI-Image-2.5 available to its developer community:
“We’re excited to bring Microsoft’s MAI models to OpenRouter. MAI-Image-2.5 is one of the strongest image models available today, and expands the set of multimodal capabilities available to developers on OpenRouter. Our goal is simple: when great new models launch, the 9 million developers building on OpenRouter should be able to use them immediately through the same API they already use.”
– Alex Atallah, CEO, OpenRouter
- As of June 2, 2026.
Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
Related Stories
Introducing MAI-Transcribe-1.5
Today we’re launching our MAI-Transcribe-1.5, the most accurate multilingual speech-to-text model with a best-in-class Word-Error-Rate (WER) across 43 languages.
This latest model has expanded the range of languages available without compromising accuracy and quality.
It’s now being integrated into Copilot, Teams, GitHub, and Dynamics 365 Contact Centre – and it’s also available in Foundry, where it’s the fastest, most efficient and most cost‑effective transcription model of any hyper-scaler.
Features and Capabilities
- SOTA accuracy as shown on FLEURS multilingual transcription benchmark, and #3 on the Artificial Analysis leaderboard.
- Leading accuracy x speed on Artificial Analysis leaderboard.
- Expanded language coverage from 25 to 43.
- Can transcribe an hour of audio in under 15 seconds. Up to five times faster on long audio than Gemini 3.1, Scribe v2, GPT-4o-Transcribe.
- Includes Keyword Biasing, enabling the model to be aware of domain specific terminology which improves WER by up to 30% on FLEURS.
- Optimized for real-world use cases such as being able to handle transcription with noisy backgrounds.
Accuracy
We expanded coverage by 18 new languages without compromising accuracy. On FLEURS – the standard multilingual benchmark – we have achieved best-in-class Word Error Rate across 43 languages, maintaining our position as the most accurate model on the benchmark.


On the Artificial Analysis leaderboard we achieved a Word Error Rate of 2.4%, achieving #3 position in a very competitive open benchmark.
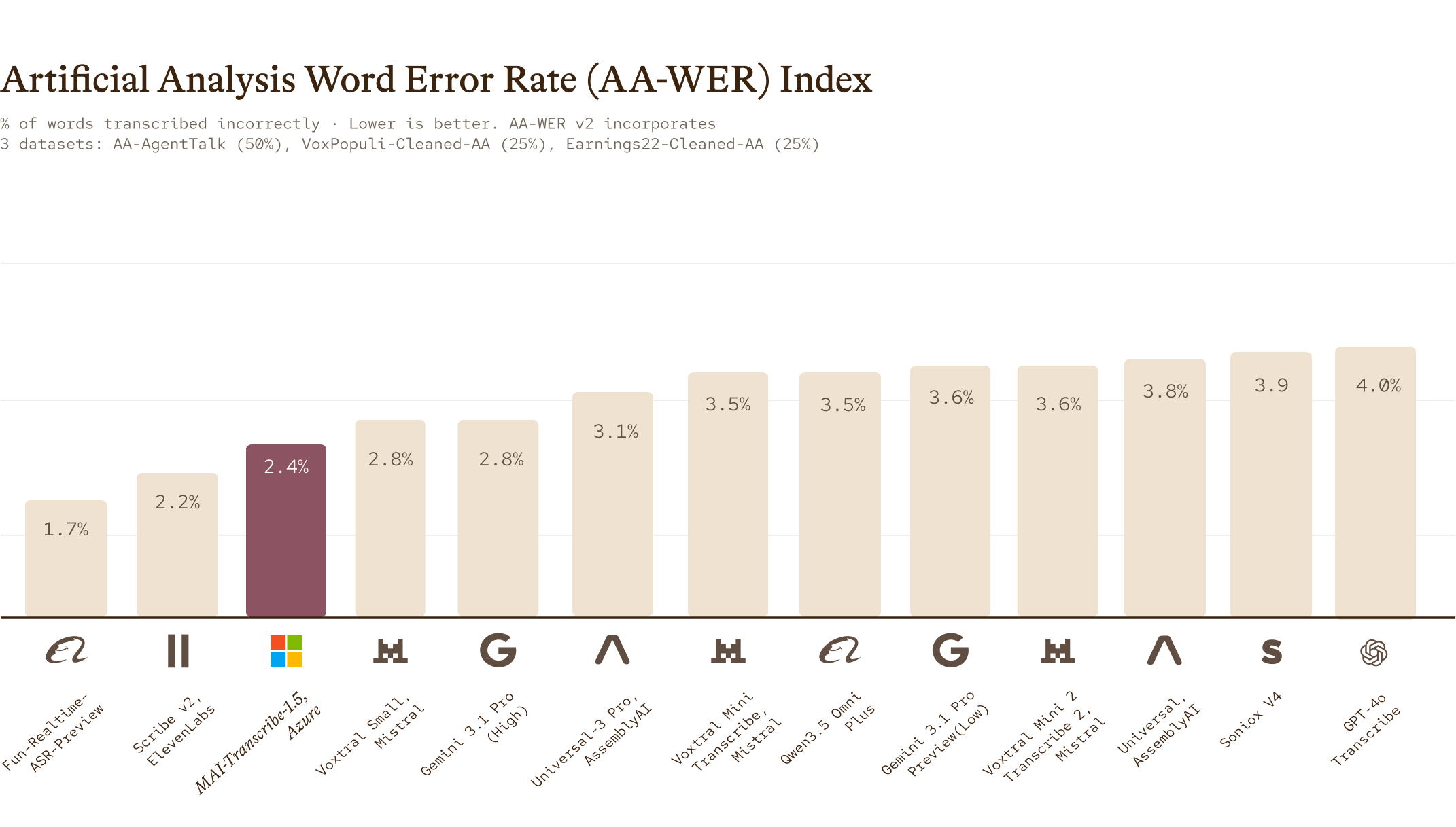
Speed
MAI-Transcribe-1.5 is now a leader in terms of accuracy x speed on the Artificial Analysis leaderboard, running up to 5x faster than models of comparable accuracy.
This is particularly impactful when transcribing long audio files, as the model can transcribe an hour of audio in under 15 seconds.
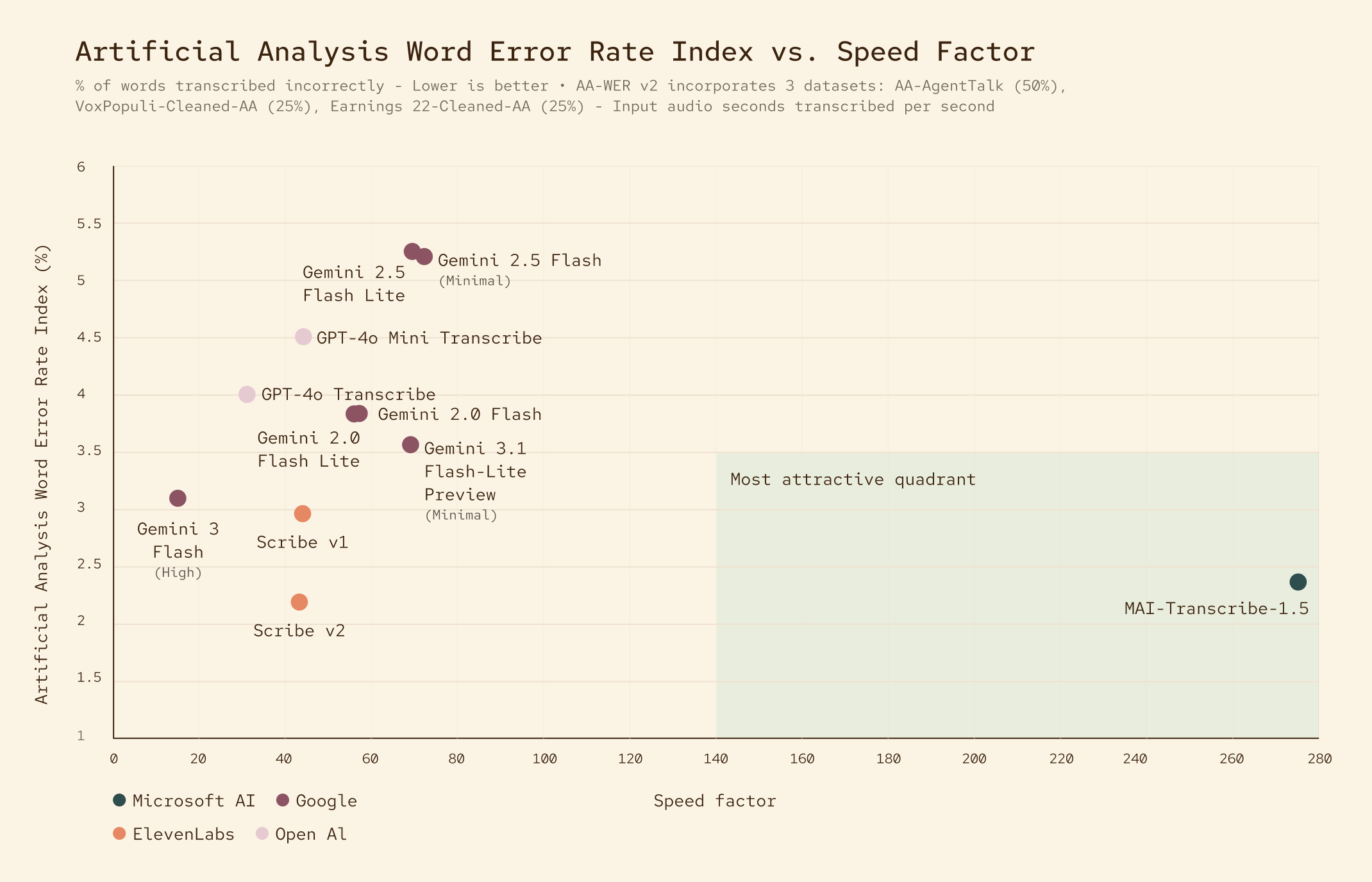

Keyword biasing
A major challenge for many transcription models is when they fail on domain specific words, which often matter the most to users. These often include people and product names, medical terms, internal acronyms, and customer-specific vocabulary which are critical for enterprises.
MAI-Transcribe-1.5 can now bias its predictions toward a list of domain specific keywords provided by the user. The model does not blindly force matches, it uses the shared context to decide when keyword biasing should apply. This dramatically improves recognition of specialized vocabulary while maintaining accuracy on general speech.
When using the keyword biasing, we observe a 30% reduction in Word-Error-Rate (WER) on the FLEURS multilingual benchmark.
English
Without keyword biasing
So, um, for the next phase, Sean will, uh, take care of the documentation. Oif, right, uh, she’ll handle the user testing sessions. Societal is, um, leading the workflow design. Soren will, uh, set up the analytics, and Niamh is going to coordinate the deployment timeline.
With keyword biasing
List of keywords: “Aisling, Shaun, Xochitl, Ljubiša, Søren, Siobhán, Jorge, Nguyễn Phúc, Aoife, Tadhg, Ghislaine, Niamh, Szczepan, Eoin, Kseniya, Wojciech, Xavier, Maoz”
So, um, for the next phase, Shaun will, uh, take care of the documentation. Aoife, right, uh, she’ll handle the user testing sessions. Xochitl is, um, leading the workflow design. Søren will, uh, set up the analytics, and Niamh is going to coordinate the deployment timeline.
What’s next
- Diarization – the ability to identify who said what in multi-speaker audio – essential for meetings, interviews, and call center analytics.
- A native streaming API, enabling real-time transcription for live applications and voice agents, moving beyond the current batch-first approach.
- Expanded language support – giving each new language the same depth of accuracy and robustness as the existing 43 languages.

Try it out
You can also explore the models directly in the MAI Playground.
Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
Related Stories
Introducing MAI-Voice-2
Today we’re launching MAI-Voice-2 — the most expressive, natural-sounding text-to-speech model we’ve built to date. It’s a significant leap from its predecessor across every dimension that matters to production voice experiences: fidelity, language coverage, speaker consistency, and emotional range. It is built for the products and services where voice quality directly impacts user experience: assistants or customer support that represent your brand, audiobooks that hold attention over hours, and accessibility experiences where voice is the only interface. It’s also built with responsible deployment in mind, with consent guardrails ensuring the technology is as trustworthy as it sounds. MAI-Voice-2 is now available in Microsoft Foundry, and is being integrated into VSCode and the Dynamics 365 Contact Center.
Features and capabilities
- Expanding from English‑only to 15 languages while maintaining the same naturalness and expressiveness as English.
- Granular emotion control via emotion tags: sad, whispered, excited, etc.
- Zero-shot voice prompting using 5-60s of reference audio available for all supported languages, with built-in consent guardrails.
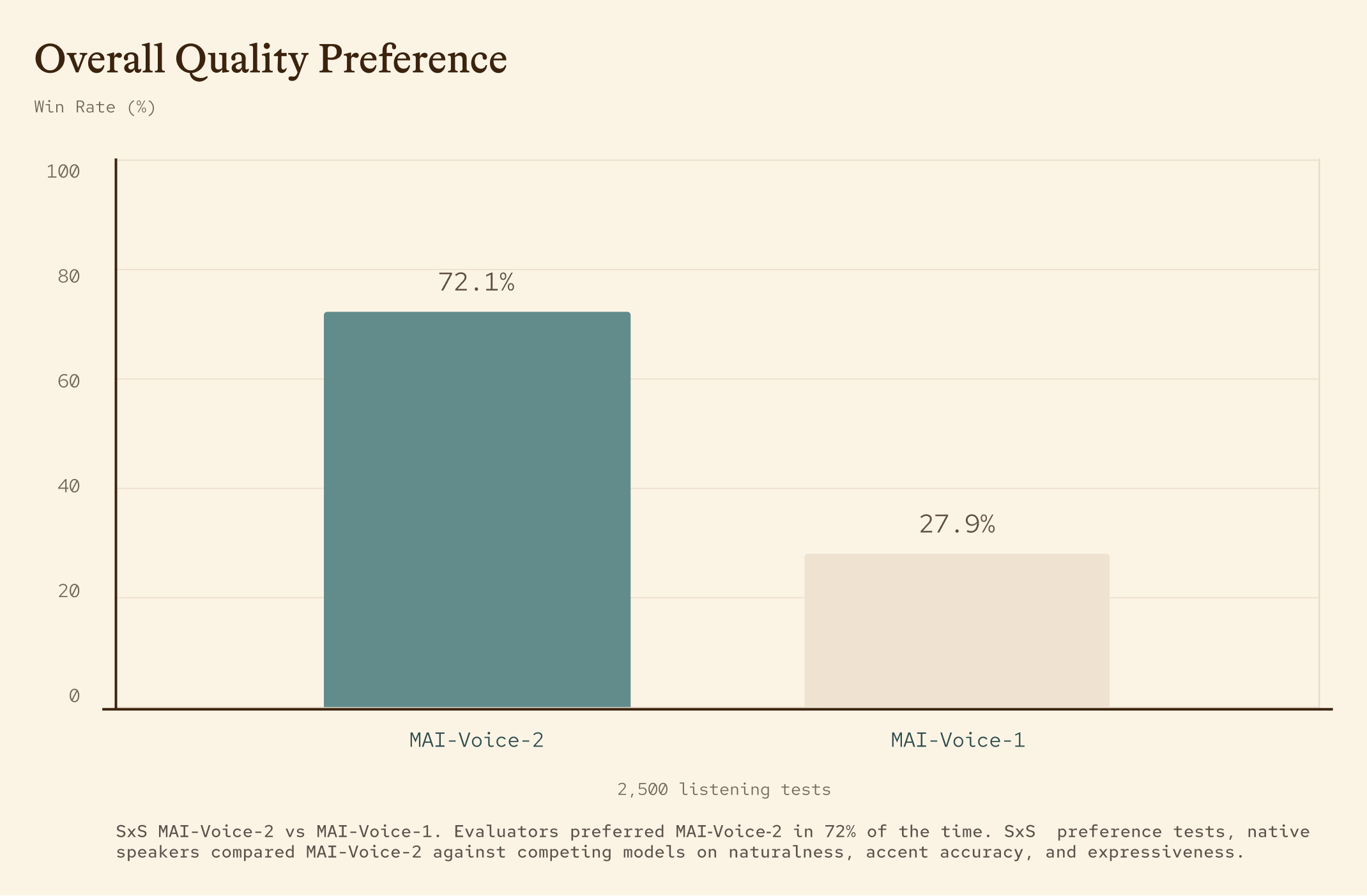
- MAI-Voice-2 is preferred over its predecessor MAI-Voice-1 72% of the time.
- Stable speaker identity across long-form content – audiobooks, podcasts, lectures.
- Code-switching capabilities for select language pairs — such as Hindi-English and Spanish-English — matching the way users naturally mix languages in everyday speech.
Hear it for yourself:
English (emotion: Embarrassed)
German (emotion: Confused)
Hindi (emotion: Excited)
English (role: Motivational Trainer)
English (role: Sports Commentator)
Performance
MAI-Voice-2 generates very natural speech in a controllable way. In side-by-side preference tests, it was preferred over its predecessors 72% of the time. In speaker similarity evaluations, speech generated by MAI-Voice-2 is indistinguishable from recordings of the same voice. Below, you can verify this yourself by trying to identify where the human speech ends and the MAI-Voice-2 output begins.
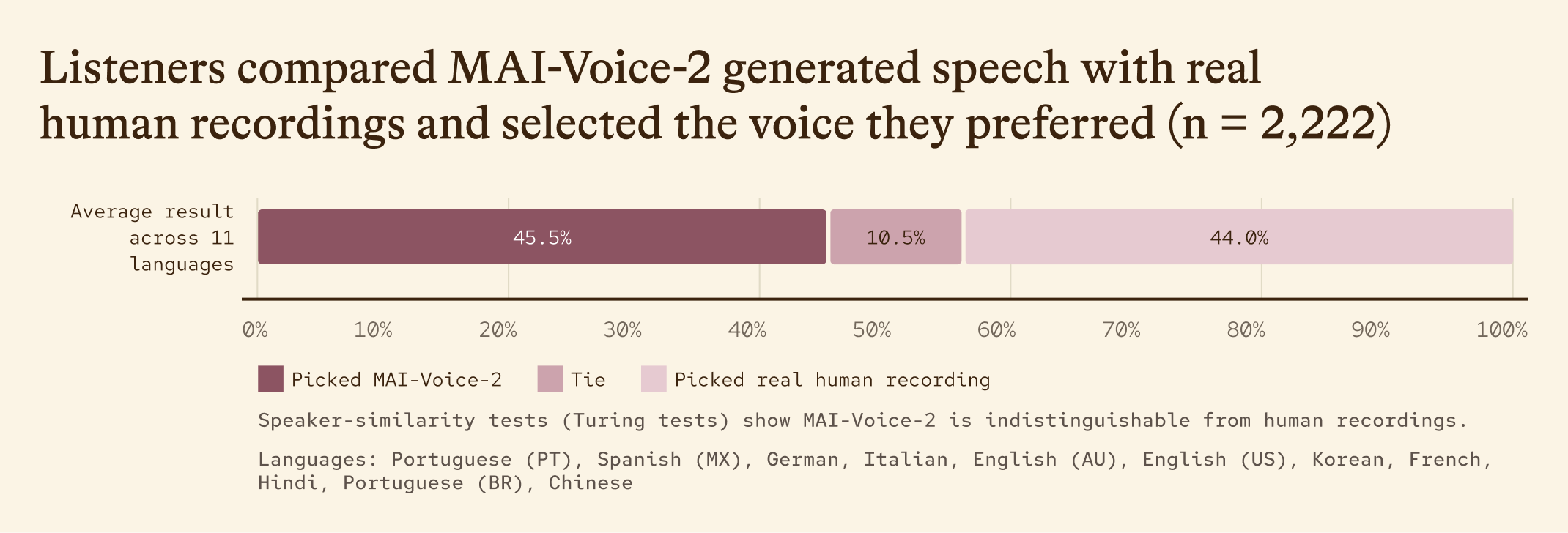
Guess the human recording vs. MAI‑Voice‑2
Listen to the audio clips below – each blends human recordings with speech generated by MAI‑Voice‑2. Can you tell where the human voice ends and the synthetic voice begins, or vice versa? Or does it sound like one continuous voice?
Human recorded + TTS
Language: English US
Human recorded + TTS
Language: Hindi (India)
Human recorded + TTS
Language: Spanish (Mexico)
TTS + Human recorded
Language: French (France)
Human recorded + TTS
Language: German (Germany)
Supported Languages
We prioritized depth across 15 languages, ensuring for supported languages we support a spectrum of expressive capabilities spanning tonal, pitch accent, stress timed, and syllable timed systems. We plan to continue expanding and refining the expressive range for all supported languages.
MAI-Voice-2 now supports the following languages/locales: English (US), English (Australia), Italian, French, German, Hindi, Spanish (Spain), Spanish (Mexico), Portuguese (Brazil), Portuguese (Portugal), Korean, Chinese (Simplified), Turkish, Russian, Thai, Dutch, Romanian and Hungarian.
In markets where people naturally mix languages, we support code-switching – notably Hindi–English and Spanish–English – reflecting how people actually speak. In internal testing, the model switches languages mid sentence fluidly, without losing prosodic naturalness nor speaker identity.
Hindi + English
Spanish (Mexican) + English
Voice Synthesis
Developers can create a custom voice in Microsoft Foundry across all supported languages using just a short reference clip – no retraining or fine tuning required. With only a few seconds of audio (recommended: 5–60 seconds), MAI Voice 2 can generate high quality speech that matches the speaker’s identity, making it easy for companies to bring their own brand voice into products without maintaining a separate voice model.
Consent and Safety
Consent is enforced at the system level: only authorized, licensed voices can be synthesized in production. No unlicensed voice cloning is possible. To gain access to this feature apply here.
Use Cases
- Assistants: Branded voices for Copilot, apps, devices, customer support.
- Entertainment: Characters for games, podcasts, audiobooks, AR/VR.
- Accessibility: Narration for visually impaired users; voice for speech impairments.
- Education: Instructors and characters for courses and simulations.
- Creators: Turn text into audio with your own voice. No studio required.
Try it out
DuoAI
DuoAI is an experimental experience that gives you a direct way to try MAI‑Voice‑2, MAI‑Transcribe‑1.5, and MAI‑Image‑2.5 models in action – showcasing natural, fluid, expressive dialogue. In the demo, you can engage in a three‑way conversation with two agents and even generate images using MAI‑Image‑2.5. It’s a practical preview of how MAI multimodal models work together to build powerful, customizable voice agents. Try DuoAI now
Note: DuoAI is not meant to showcase the capabilities of the underlying LLM – that component is modular and can be swapped as needed.
You can also explore the models directly in the MAI Playground.
Learn more about MAI-Voice-2
Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!
